Приручение трансформеров
Архитектура трансформера поражает своей мощью, но известна своей медлительностью. Исследователи разработали множество изменений, чтобы ускорить его работу, достаточно для того, чтобы рассмотреть, как эти альтернативы работают, их преимущества и недостатки.
Что нового: Квентин Фурнье, Гаэтан Марсо Карон и Даниэль Алоиз провели обзор вариаций трансформера, оценивая методы, разработанные для его ускорения и повышения эффективности. В данном обзоре фокус сосредоточен на вариациях, предназначенных для ускорения работы.
Стоимость внимания: Механизм внимания в исходном трансформере представляет собой огромную нагрузку на вычисления и память; его стоимость O(n2), где n - длина входной последовательности. Когда трансформер обрабатывает каждый токен (часто слово или пиксель) во входной последовательности, он одновременно обрабатывает - или "обращается" к - каждому другому токену в последовательности. Внимание рассчитывается путем умножения двух больших матриц весов, после чего полученная матрица проходит через функцию "softmax". Функция softmax нормализует значения матрицы до вероятностного распределения, приближая более высокие значения к 1 и более низкие значения к 0. Это позволяет трансформеру при кодировании токена использовать соответствующие токены и игнорировать несущественные токены.
(Модифицированное) внимание - это все, что вам нужно: Авторы выделяют три подхода к ускорению работы трансформеров. Два из них оптимизируют механизм внимания, а третий оптимизирует другие части архитектуры.
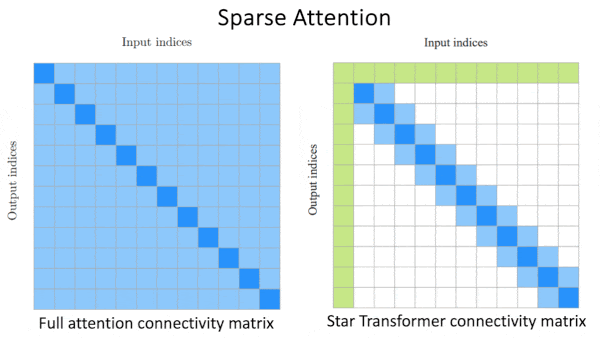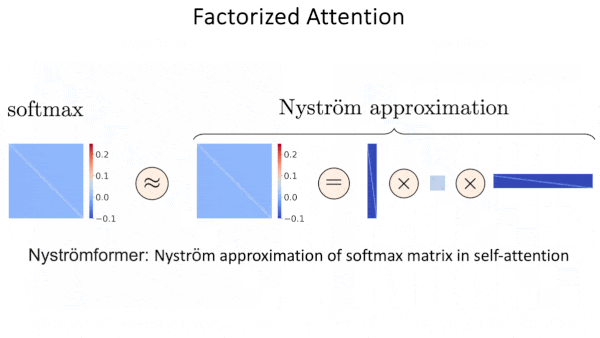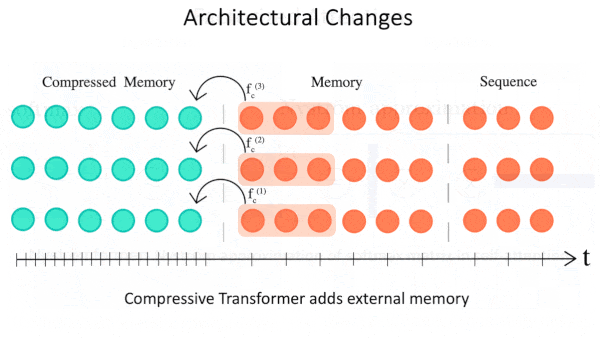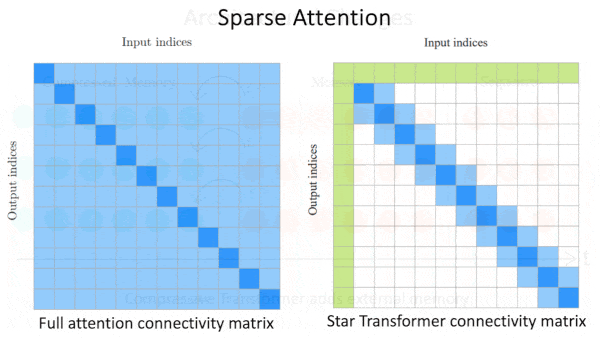
- Разреженное внимание. Эти подходы упрощают вычисление внимания, используя подмножество весов и устанавливая остальные в 0. Они комбинируют три общих шаблона, в которых положение данного токена в последовательности определяет, как он обращается к другим токенам: (i) токен обращается ко всем остальным токенам, (ii) токен обращается только к непосредственным соседним токенам, или (iii) токен обращается к случайно выбранному набору токенов. Например, в Star Transformer первый токен обращается ко всем остальным токенам, а остальные токены обращаются только к соседям. Вычисление внимания с использованием разреженных матриц происходит быстрее благодаря алгоритмам быстрого умножения разреженных матриц. Однако, поскольку обрабатываются только подмножество исходных весов внимания, этот подход незначительно снижает производительность. Кроме того, поскольку разреженные шаблоны внимания создаются вручную, они могут не работать хорошо с каждыми данными и задачами.
- Факторизованное внимание. Подходы в этой категории модифицируют вычисление внимания, приближая отдельные матрицы как произведение двух (или более) меньших матриц. Эта техника позволяет Linformer уменьшить требования к памяти в 10 раз по сравнению с исходным трансформером. Методы факторизованного внимания превосходят разреженное внимание в некоторых задачах, таких как определение, связаны ли две точки на изображении пунктирной линией. Однако, они менее эффективны в других областях, таких как классификация изображений и сжатие длинных последовательностей для поиска.
- Архитектурные изменения. Эти подходы сохраняют исходный механизм внимания, изменяя другие аспекты архитектуры трансформера. Один из примеров - добавление внешней памяти. В исходном трансформере, если входная последовательность слишком длинная, модель разбивает ее на более мелкие части и обрабатывает их независимо друг от друга. При обработке длинного документа к концу модель уже не помнит, что происходило в начале. Transformer-XL и Compressive Transformer сохраняют эмбеддинги предыдущих частей входа и используют их для эмбеддинга текущей части. По сравнению с исходным трансформером того же размера, Transformer-XL смог улучшить свою производительность на основе обучающих примеров, в 4,5 раза длиннее.
Однако: Сложно сравнивать результаты, достигнутые этими вариациями, из-за различий в размере модели, гиперпараметрах (которые влияют на производительность) и используемом оборудовании (которое влияет на скорость). Кроме того, некоторые вариации трансформера используют несколько модификаций, что затрудняет выделение преимущества какой-либо конкретной.
Почему это важно: Эти вариации могут помочь инженерам машинного обучения управлять вычислительными требованиями, в то время как они используют передовые подходы.
Мы думаем: Авторы проекта Long Range Arena создали панель управления, которая отражает производительность различных трансформеров в зависимости от задачи. Мы приветствуем дальнейшие усилия по помощи разработчикам в понимании компромиссов, связанных с различными вариациями.